EVD and SVD Applications
Textbook: pp.298 - 322
Keywords: principal component analysis, linear discriminant analysis
Long time no see !!!. 이 포스팅은 드디어 이 참으로 못쓴 책의 마지막 챕터이다. 목표로 하던 연재시점 (…?, 너무 거창한 표현같지만) 보다는 20일 가량 늦어졌는데, 30대의 위기랄까? 잠시 심마에 빠져 허우적대느라 그리되었다. 최근에 어찌저찌 주회입마에서 간신히 빠져나왔기에 이제 다시 열심히 포스팅을 해보려고 한다.
이 챕터의 내용은 앞서 배운 내용인 EVD와 SVD의 응용을 소개하고 설명하는 것이다. 하지만, SVD 응용은 SVD 챕터 에서 살펴본 행렬 분해에 대한 연습문제가 전부이고, 따로 설명하지도 않는다. (역시 끝까지 기대를 저버리지 않고 거지같다 :D). 그래서 사실상 이 챕터의 내용은 EVD의 응용이고, 두 가지 사례로서 (1) PCA (Principal Component Analysis), (2) LDA (Linear Discriminant Anaysis) 가 소개된다.
PCA의 경우, 역시나 책의 설명이 끔찍했기에 블로그, 유튜브 등을 통하여 보다 자세히 학습하였다. PCA를 이해할 수 있는 몇가지 방법을 익혔는데, 필자는 이들 중 가장 와닿았던 기하학적인 방법을 통해 설명해 볼 것이다.
LDA의 경우 블로그나 유튜브 강의를 보아도 엄밀히 이해하는 것은 어려웠는데, 다행히 이 책에 나온 내용 중 일부를 받아들임으로서 조금 쉽게 설명할 수 있다. 필자가 굳이 “받아들인다”는 표현을 쓴 데에는 이유가 있는데, 이것을 정획히 이해하지 못하고 그냥 결과를 받아들였기 때문이다.
그럼 차근차근 시작해보도록 하자.
I. What is PCA?
PCA는 주어진 데이터의 차원을 축소하는 기법이다 (i.e. N 차원 데이터 -> M <= N 차원 데이터). 필자의 경우 PCA를 자세히 뜯어보기 전엔 “차원을 축소한다”는 표현이 참 추상적이었는데, 결국 공부하고 보니 이 표현만큼 적절한 표현이 없는 것 같다. 왜 그런 것 있지 않은가? 경험해봐야지만 이해할 수 있는 표현들.
아래 그림의 좌측과 같이 학생들의 물리, 수학 점수가 데이터로 주어졌다고 가정해보자. 그리고, 아래 그림의 우측과 같이 이 데이터를 평균중심화 해두었다고 가정하자 (실제 PCA는 모두 데이터가 평균중심화 된 상태임을 가정함).
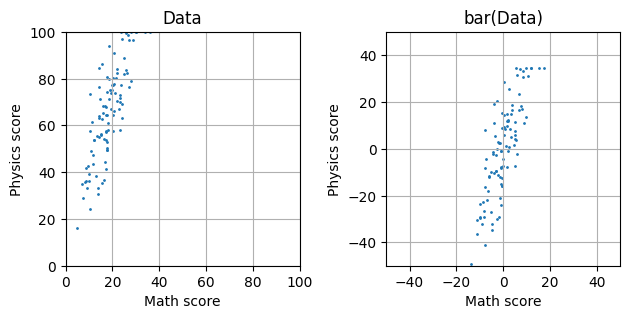
이제 TA가 되어서 이 학생들에게 학점을 나누어주어야 한다고 생각해보자. 아마 당신은 적당히 과목별로 가중치를 정해서 weighted sum을 구한 뒤에 학생들을 줄세워 A+, A0, … 와 같이 학점을 부여할 것이다. 그런데, 사실 weighted sum을 구한 뒤에 줄을 세우는 행위는 기하학적으로는 특정한 weight 벡터에 학생들의 점수 벡터를 사영을 내리는 행위로 볼 수 있다. 예를 들어, 수학과 물리 점수에 1:1로 가중치를 두고 줄을 세운다는 것은 아래 그림의 첫번째 그래프와 같이 빨간 벡터에 각 데이터들을 사영한 뒤에 사영된 수직선 위에서 줄을 세우는 것과 같다. 이해를 돕기 위해 아래 그림에 1:2, 1:4 따위의 가중치를 함께 예시하였다.
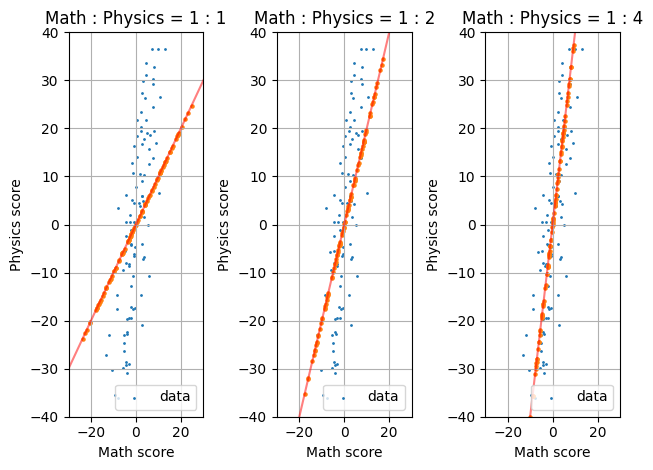
당신이 TA라면, 그래서 학생들을 줄 세워 학점을 나누어주어야 한다면, 당신은 어떤 가중치를 고르겠는가? 아마도, 대부분의 사람들은 직관적으로 1:4 의 가중치를 고를 것이다. 그리고 이 가중치를 고른 이유는 학생들의 분포가 최대한 뭉게지지 않고 이쁘게 유지되기 때문일테다. 이것을 수학적으로 표현하면, “사영한 데이터의 분산이 최대화 되는 가중치였기 때문” 정도가 되리라.
설명의 편의를 위해 2차원 데이터를 1차원 데이터로 축소하는 것의 예를 들었는데, 일반화하면 PCA는 N차원 데이터에 대해서 아래의 과정으로 설명할 수 있다.
- 분산을 최대화 하는 기준 벡터 하나를 찾는다.
- 위에서 찾은 기준 벡터 방향의 분산을 제외한 나머지 분산을 최대화하며 이전에 찾은 기준 벡터들과 직교하는 기준 벡터를 또 찾는다.
- 위에서 찾은 기준 벡터 방향의 분산을 제외한 나머지 분산을 최대화하며 이전에 찾은 기준 벡터들과 직교하는 기준 벡터를 또 찾는다.
- …
여기서, “위에서 찾은 기준 벡터 방향의 분산을 제외한 나머지 분산을 최대화 하며” 따위의 표현이 대단히 모호한데, 이것의 직관을 제대로 그려낼 자신이 도무지 없다. 하지만 아래와 같이 한번 설명을 시도해보겠다.
- 3차원 데이터를 생각해보자.
- 어떤 공간상에 흩뿌려져 있는 점군을 생각하면 편하리라.
- 어찌저찌 (뒤에서 설명할 방법으로) 하나의 기준 벡터를 찾았다고 해보자.
- 이제 두 번째 기준 벡터를 찾아야 하는데, 이때 “위에서 찾은 기준 벡터 방향의 분산을 제외”하기 위해서 아래의 방법을 사용해보자.
- 첫 번째 기준벡터에 수직인 평면을 생각하자.
- 모든 데이터를 이 평면에 짜부시키자 (사영하자).
- 그러면, 이제 이 문제는 다시 2차원 데이터에서 기준 벡터를 찾는 문제가 된다.
II. How to do PCA?
이제 실제로 PCA를 수행하는 법에 대해서 알아보도록 하자. PCA를 수행한다는 말은 위에서 언급했듯이 곧 “데이터를 사영할 \(M\)개의 기준 벡터들을 찾는” 과정이다. 이 기준 벡터들을 찾는 과정을 대수학적으로 벡터 미분 등을 동원하여 설명할 수도 있지만, 개인적으로 필자는 기하학적인 설명이 보다 기억에 오래간다고 믿는다. 미리 경고하자면, 이 설명은 대단히 엄밀하지 못하고 직관에 의존한 설명이다. 만약, 보다 엄밀한 설명이 필요하다면 대수학적인 해석을 참고하기 바란다.
II.1. Geometric view on covariance matrix
일전에 공분산 행렬에 대해서 소개한 적이 있다. 그때는 주로 상관계수와의 차이점을 살피며 설명했었는데, 이번에는 기하학적인 해석에 초점을 맞추어보도록 하자.
결론부터 이야기하면 공분산 행렬은 데이터가 어느 방향으로 퍼져 있는지를 재현할 수 있는 선형변환으로 이해할 수 있다. 이게 뭔 뚱딴지같은 소리야 싶은 것이 당연하다. 조금만 참고 예제를 살펴보자.
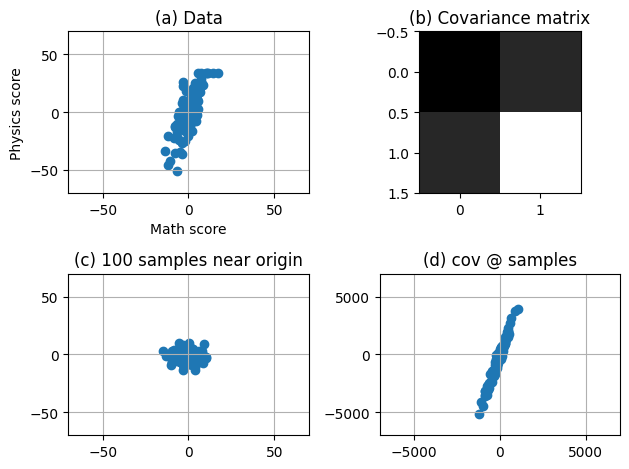
다시 물리, 수학 성적 데이터를 아래 (a) 에 가져왔다. 그리고, 이 데이터의 공분산 행렬을 (b)와 같이 구해보았다. 이제 (c)와 같이 원점 부근에 에 다닥다닥 모여있는 100개의 데이터가 있다고 해보자. (c)의 각 데이터에 공분산 행렬을 곱해주면 (선형변환을 태워주면) (d)와 같이 데이터가 특정한 방향으로 퍼지게된다. 최종적으로 (a)와 (d)를 비교해보라. 두 데이터의 퍼진 방향이 굉장히 일치하지 않는가? 이처럼 공분산 행렬은 데이터가 어느 방향으로 퍼져 있는지를 알려주는 선형변환으로 이해할 수 있다.
II.2. Geometric view on eigen matrix
자 위에서 이제 공분산 행렬이 데이터가 어느방향으로 퍼져있는지를 설명해주는 행렬이라는 것을 알아냈다. 그럼 이제 아래 식을 펼쳐놓고 공분산 행렬의 고유값과 고유벡터들에 대해서 생각해보도록 하자.
\[Cov(\bar{d}) \mathbf{v} = \lambda \mathbf{v}\]고유벡터에 대한 직관적인 해석 을 소개할 떄 이야기했듯이 위 식으로부터 공분산 행렬의 고유벡터 \(\mathbf{v}\) 는 공분산 행렬의 선형변환으로 인해 방향이 바뀌지 않고 크기만 늘어나는 고유한 벡터이다.
예를 들어, 바로 위 그림의 (c)에서 데이터가 늘어나는 방향으로 하나의 벡터를 선정했다고 해보자. 그 벡터에 공분산 행렬이 나타내는 선형변환을 태워주어도 방향은 변경되지 않고 크기만 변경될 텐데, 이는 곧 선정한 벡터가 공분산 행렬의 고유벡터였기 때문이다.
II.3. Summary
PCA를 위한 기준 벡터들은 데이터의 공분산 행렬을 EVD 하여 얻을 수 있다. 고유값의 크기가 큰 고유벡터들이 더 주된 성분이라고 볼 수 있다.
III. What is LDA?
LDA (선형판별분석) 은 사실…이것의 도출 과정을 이해했다면 거짓말이고, 어느 순간 받아들였다. 포스팅에서도 딱 그 정도 수준으로만 설명할 것이다. 아마도, 추후에 머신 러닝등을 공부하면서 보다 심층적으로 이해할 날이 오리라.
아래와 같이 생겨먹은 학습 데이터가 있다고해보자. 이 데이터는 각 데이터가 0 group 에 속하는지 1 group 에 속하는지 라벨을 가진 데이터이다. x축을 친구 수, y축을 학점 정도로 생각하고, 0-1 을 대학원 진학 여부로 생각한다면 나름 말이 되는 데이터일 것이다 (보통 대학원은 친구 업고 학점 낮은 인간들이나 가는 곳이니까).
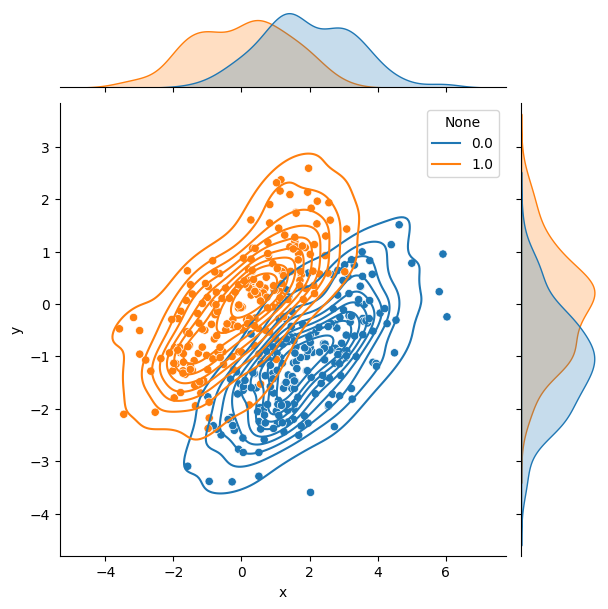
이제 이 학습 데이터로부터 할 일은 두 그룹의 데이터를 최대한 잘 분리해 낼 수 있는 기준벡터를 찾는 것이다. 이 벡터를 찾아두면, 추후 임의의 (그룹을 모르는) 데이터가 추가되었을 때 이 데이터의 그룹을 추론해낼 수 있게 된다. 가령 위의 예제에서 \(y = -x\) 따위의 직선이 나타내는 벡터 (i.e. \([1\ -1]^T\))를 찾아 둔다면, 추론할 데이터의 이 벡터 위로의 사영이 0보다 큰가 작은가를 기준으로 그룹을 추론해낼 수 있을 것이다.
굳이 증명 없이 직관적으로 알 수 있는 사실은 기준 벡터로 데이터들을 사영하였을 때 그룹 내 분산은 최소화 되고 (같은 그룹끼리는 몰려 있어야 하니까), 그룹 간 분산은 최대화 되는 (다른 그룹끼리는 멀리 떨어져 있어야 하니까) 기준 벡터를 찾아야 한다는 것이다.
이 때, 그룹 내 분산 (\(C_{within}\)) 은 각 그룹의 공분산을 개별적으로 계산한 뒤에 이들의 평균을 구하면 된다. 그룹 간 분산 (\(C_{between}\)) 은 각 그룹 내에서 데이터의 평균을 계산하고, 각 그룹을 열로, 각 평균을 행으로 갖는 행렬을 만든 뒤 그 행렬의 공분산 행렬을 구하면 된다.
IV. How to do LDA?
뭐 식이 어찌저찌 복잡한데, 여기서 적지는 않을 것이다. 결과적으로는 \(\mathbf{C}_{within} \mathbf{V} \mathbf{\Lambda} = \mathbf{C}_{between} \mathbf{V}\) 를 만족하는 \(\mathbf{V}\) 의 열 벡터들이 곧 구하고자 하는 기준 벡터들이 된다고 한다.
그런데, 일반화된 고유값 분해 (이것이 무엇인지 당최 모르겠지만) 라는 과정이 두 행렬 \(\mathbf{C}_{within}\) 과 \(\mathbf{C}_{within}\) 에 대해서, \(\mathbf{C}_{within} \mathbf{V} \mathbf{\Lambda} = \mathbf{C}_{between} \mathbf{V}\) 를 만족하는 \(\mathbf{V}\) 와 \(\mathbf{\Lambda}\) 를 구해줄 수 있다고 한다.
V. Exercises
이 챕터의 연습문제 풀이는 여기에서 확인할 수 있다.