GLM (General Linear Model)
Textbook: pp.211 - 229
Keywords: glm, general linear model
뜬금 없이 모르는 약어가 등장하며 퍼뜩 겁을 집어먹게 만드는데, GLM은 단순히 General Linear Model의 약자이다. “아이씨, 나는 General Linear Model도 뭔지 모르는데?” 하며 겁먹지 말자. 앞선 챕터에서 보아온 내용을 크게 벗어나지 않는 수준일 것이다.
I. General Linear Model (GLM)
아무리 생각해도 “자 이제부터 GLM이 무엇인지 그 정의를 읊어보겠습니다.” 따위의 기술은 이를 익히는데 전혀 도움이되지 않는다 (마치 운전을 배우는 과정에 비유해볼 수 있으리라).
곧바로 예제부터 살펴보도록 하겠다. 개똥이는 어머니, 아버지의 키로부터 자녀의 키를 추정하는 공식을 만들고 싶었다. 일단, 개똥이는 아래와 같이 (무지성으로) 많은 수의 부모 및 자녀 키 데이터를 수집했다.
| 자녀의 키 | 어머니의 키 | 아버지의 키 |
|---|---|---|
| 175 | 160 | 170 |
| 177 | 159 | 175 |
| … | … | … |
| 181 | 163 | 180 |
그리고, 개똥이는 자녀의 키 (\(y\)) 와 어머니의 키 (\(m\)),아버지의 키 (\(d\)) 사이에는 아래와 같은 선형 관계가 있으리라 추정하고 있다. 여기서 \(\beta_1\), \(\beta_2\) 따위는 아직 정해지지 않은 계수이다.
\[y = \beta_1 + \beta_2 m + \beta_3 d\]이제 개똥이는 수집한 데이터를 이 식에 끼워넣은 뒤에 본인의 추정 (선형관계) 을 가장 잘 만족시키는 \(\beta\) 를 찾으려고 한다. 우선, 개똥이의 추정을 행렬을 사용해서 표현해보자.
\[\left[ { \begin{array}{ccc} 1 & 160 & 170 \\ 1 & 159 & 175 \\ 1 & ... & ... \\ 1 & 163 & 180 \\ \end{array} } \right] \left[ { \begin{array}{c} \beta_1 \\ \beta_2 \\ \beta_3 \\ \end{array} } \right] = \left[ { \begin{array}{c} 175 \\ 177 \\ ... \\ 181 \\ \end{array} } \right]\]
- 보통 관례에 따라, 위와 같은 식은 \(\mathbf{X} \mathbf{\beta} = \mathbf{y}\) 의 형태로 많이 쓰인다.
- \(\mathbf{X}\) 를 보통
설계 행렬이라고 부른다.- \(\mathbf{\beta}\) 를 보통
회귀 계수라고 부른다.- \(\mathbf{y}\) 를 보통
종속 변수라고 부른다.
이렇게 선형관계에 놓여 있는 데이터를 설계 행렬 따위를 통해 행렬로 표현하고 풀어내는 것이 바로 GLM (General Linear Model) 되시겠다. 예제를 보고 눈치챘겠지만, GLM 은 정말 여러 곳에서 유용하게 사용되고 있다.
II. How to solve GLM ?
이제 본격적으로 GLM을 어떻게 풀 수 있는지 알아보도록 하자. \(\mathbf{X} \mathbf{\beta} = \mathbf{y}\) 형태로 주어지는 GLM을 푼다는 것은 곧 \(\mathbf{\beta}\) 를 구한다는 것이다. 그리고, \(\mathbf{\beta}\) 는 아래와 같이 구할 수 있다 (우선, 결론만 적는 것이니 이해는 나중에 해라).
이 책의 저자는 독자에게 위 식을 이해시키기 위해 총 3가지의 설명 방법을 소개한다. 필자의 경우 하나의 결론 (결과 식) 을 여러가지 방법으로 생각해보는 과정이 꽤나 즐거웠기에 이를 기록하여 남긴다.
II.1. 미적분을 써서 이해해보자.
\(\mathbf{X} \mathbf{\beta} = \mathbf{y}\) 라는 식에서 시작해보자. 자명하게, 개똥이의 추정은 오차를 가질 것이고 그 때의 오차는 \(\mathbf{X} \mathbf{\beta} - \mathbf{y}\) 라고 적어줄 수 있다. 가장 좋은 \(\mathbf{\beta}\) 는 이 오차 제곱을 최소화하는 \(\mathbf{\beta}\) 라고하자. 그럼 자연스레 최적화 문제 \(\min_{\mathbf{\beta}} || \mathbf{X} \mathbf{\beta} - \mathbf{y} ||^2\) 이 유도된다. 간단한 2차 함수이니 미분계수가 0 이 나오는 지점에서 최솟값을 갖고, 이 지점을 구하는 방법은 아래와 같다. 아래의 식 전개에서는 벡터 미분이 자주 사용되는데, 모르더라도 기죽지 말고 일단 받아들이기를 바란다 (필자도 맨날 까먹는다).
\[\begin{align*} \mathbf{0} & = \frac{d}{d \mathbf{\beta}} || \mathbf{X} \mathbf{\beta} - \mathbf{y} ||^2 \\ \mathbf{0} & = 2 \mathbf{X}^T (\mathbf{X} \mathbf{\beta} - \mathbf{y}) \\ \mathbf{X}^T \mathbf{X} \mathbf{\beta} & = \mathbf{X}^T \mathbf{y} \\ \mathbf{\beta} & = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y} \\ \end{align*}\]II.2. 왼쪽 역행렬을 통해 이해해보자.
사실 \(\mathbf{X} \mathbf{\beta} = \mathbf{y} \Rightarrow \mathbf{\beta} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y}\) 의 유도는 단지 양변에 왼쪽 역행렬을 곱해준 것만로 한 방에 설명해줄 수 있다! 왼쪽 역행렬에 대한 설명은 지난 포스트 를 참고하도록 하자. 이 설명은, 왠만해서는 까먹어지지 않을 정도로 강력해서 필자가 가장 선호하는 설명 방법이기도 하다.
II.3. 기하학적으로 직교 분해를 통해서 이해해보자.
이 설명은 아름답지만, 꽤나 많은 상상력을 필요로한다. 그래도 차근차근 생각해보면 어렵지 않으니 잘 따라와보기를 바란다. 우리가 하고자 하는 것은 \(|| \mathbf{y} - \mathbf{X} \mathbf{\beta} ||\) 가 최솟값을 갖도록 \(\mathbf{\beta}\) 의 값을 정하는 것이다. 이 목표를 잊지 말고, \(\mathbf{X} \mathbf{\beta}\) 가 갖는 의미부터 생각해보자. \(\mathbf{X} \mathbf{\beta}\) 는 \(\mathbf{X}\) 의 각 열로 만들어내는 선형 결합으로 이해할 수 있다. 따라서, 임의의 \(\mathbf{\beta}\) 를 상정한다면 \(\mathbf{X} \mathbf{\beta}\) 는 \(\mathbf{X}\) 의 열공간 \(C(\mathbf{X})\) 으로 이해할 수 있다. 이제 다시 원래의 목표를 다른 문장으로 표현해보자.
\(|| \mathbf{y} - \mathbf{X} \mathbf{\beta} ||\) 가 최솟값을 갖도록 \(\mathbf{\beta}\) 의 값을 정하는 일을 달리 표현하면:
- \(C(\mathbf{X})\) 안에 있는 벡터 중 \(\mathbf{y}\) 에 가장 가까운 벡터를 찾고,
- 그 벡터를 통해서 \(\mathbf{\beta}\) 를 알아내는 일이다.
그렇다면 위에서 언급한 가장 가까운 벡터는 대채 무엇일까? 그렇다, 이것은 바로 \(\mathbf{y}\) 의 \(C(\mathbf{X})\) 위로의 사영이다! 혹자는 “미친놈이 잘 이해도 안되었는데 느낌표를 갈기고 지랄이야” 라고 생각할 수도 있다. 그래서, 필자가 그림을 준비해보았다.
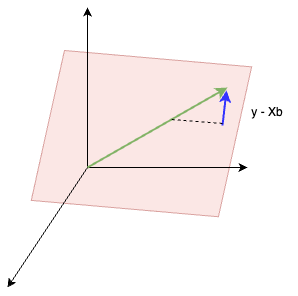
- 위의 그림에서 적색 평면을 \(C(\mathbf{X})\), 녹색 화살표를 \(\mathbf{y}\) 라고 하자.
- 자명하게 \(C(\mathbf{X})\) 내에서 \(\mathbf{y}\) 에 가장 가까운 벡터는 \(\mathbf{y}\) 의 \(C(\mathbf{X})\) 위로의 사영일 것이다.
그러면, 대체 이 벡터를 어떻게 구할 수 있을까? 우리는 첫 번째 챕터에서 직교분해를 배웠다. 이 직교분해를 그대로 이용하면 \(\mathbf{y} - \mathbf{X} \mathbf{\beta}\) 와 \(\mathbf{X}\) 가 직교한다는 사실로부터 다음을 얻는다.
\[\begin{align*} \mathbf{0} & = \mathbf{X}^T (\mathbf{y} - \mathbf{X} \mathbf{\beta}) \\ \mathbf{X}^T \mathbf{X} \mathbf{\beta} & = \mathbf{X}^T \mathbf{y} \\ \mathbf{\beta} & = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y} \end{align*}\]III. Exercises
이 챕터의 연습문제 풀이는 여기에서 확인할 수 있다.